
|
|
|
You are hereSztuczne Życie i algorytmy inspirowane biologicznieCytowanie artykułu: Komosiński M., Sztuczne Życie. Algorytmy inspirowane biologicznie. Nauka 4/2008, Polska Akademia Nauk, Warszawa, pp. 7–21. [BibTex] 1. Czym jest sztuczne życie?Najczęściej zaczynając rozmowę o sztucznym życiu, pytamy najpierw „a czym jest życie?” Nie ma takiej definicji życia, która by w ścisły sposób określiła ten fenomen i zarazem znalazła uznanie wśród wszystkich badaczy. Powstało za to wiele definicji skupiających się na poszczególnych aspektach życia – metabolizmie, aktywności w środowisku, genetyce, ewolucji i dziedziczeniu informacji, zdolności do samoorganizacji i przetrwania w postaci zorganizowanej pomimo niszczącego wpływu otoczenia, itp. Nie w każdej sytuacji można łatwo określić czy coś jest, czy nie jest żywe; łatwiej ocenić „stopień” życia lub podać listę wyznaczników (cech) życia, które badany obiekt posiada. Potocznie, kiedy mówimy o sztucznym życiu, w pierwszej kolejności – osobom, które wcześniej nie zgłębiły tej tematyki – przychodzi na myśl życie sztucznie wytworzone. Oznacza to syntetyczne życie biochemiczne – twory, którymi zajmuje się biologia syntetyczna, a zatem formy życia które nie różnią się od form naturalnych, lecz ich sposób powstania (pochodzenie) jest inny. Jednak sztuczność takich form życia jest dyskusyjna – przecież nie różnią się od swoich odpowiedników naturalnych. Zatem trudne (lub niemożliwe... zależy to od sposobu syntezy) byłoby odkrycie ich nienaturalnego pochodzenia poprzez późniejsze badania (chyba, że byłby to jakiś oryginalny organizm nie znany do tej pory na Ziemi). Oprócz biologicznego życia syntetycznego, życie sztuczne kojarzy się również z maszynami, które posiadają zdolność samopowielania i autonomicznego funkcjonowania w środowisku, a także z niematerialną sztuczną inteligencją, która dorównuje wysoce rozwiniętym istotom żywym. Choć w języku mówionym nie usłyszymy różnicy, w piśmie możemy wyróżnić wielkimi literami inne znaczenie Sztucznego Życia – mianowicie kierunek badań, który zajmuje się budowaniem modeli życia we wszelkich dostępnych środowiskach (mediach). Ta konwencja stosowania małych lub dużych liter w celu rozróżnienia dwóch znaczeń jest wykorzystana w tym artykule. Do budowania modeli życia wykorzystuje się przede wszystkim środowiska programowe (software), sprzętowe (hardware) i biochemiczne (wetware). Co ciekawe, kolejność jest tu odwrotna od tej, jaką widzieliśmy w intuicyjnym rozumieniu terminu „sztuczne życie”: tam przede wszystkim myśleliśmy o formach biologicznych, później o robotach, a w końcu o niematerialnych programach. Tu najpopularniejsze jest środowisko programowe (jest tanie i bardzo elastyczne), część badań prowadzi się przy wykorzystaniu robotów, a najrzadziej eksperymentuje się w laboratorium biochemicznym. Pierwsza konferencja poświęcona Sztucznemu Życiu (Artificial Life, AL, Alife) odbyła się w Los Alamos w roku 1987 z inicjatywy amerykańskiego biologa, Christophera Langtona [6]. Konferencję nazwano International Conference on the Synthesis and Simulation of Living Systems, choć obecnie określana jest często jako „Artificial Life I”. Patrząc na zakres zainteresowań Sztucznego Życia, w ostatnim roku zauważyć można wyraźne skupienie uwagi na osiągnięciach biologii syntetycznej – i choć „mokra” część badań Sztucznego Życia wcześniej nie dotyczyła syntezy naturalnych form życia, wydaje się że ten nurt zostanie do Sztucznego Życia wkrótce włączony. Czym zatem zajmowało się Sztuczne Życie w zakresie środowisk (bio)chemicznych (wetware)? Badano obliczenia chemiczne, a więc takie przetwarzanie informacji, w którym medium są substancje chemiczne. Zaletą tego podejścia jest masywna równoległość oraz odporność na zakłócenia; można znaleźć analogie do modelu automatów komórkowych, a podejście do obliczeń przypomina modele wykorzystujące cząsteczki biologiczne, lecz jest ogólniejsze. Zgrubnie środowiska, w których przebiegają obliczenia chemiczne, dzieli się na takie, w których
W takich środowiskach można rozwiązywać realne zadania obliczeniowe (budować oscylatory chemiczne, bramki logiczne, przetwarzać obrazy, a nawet uruchamiać „algorytmy” śledzenia celu, omijania przeszkód czy szukania optymalnej drogi). Choć środowisko jest biochemiczne, nie ma tu mowy o syntezie życia, raczej o wykorzystaniu podstawowych właściwości środowiska do prowadzenia ogólnie rozumianych obliczeń.
1.1. Definicja Sztucznego ŻyciaWypunktujmy najważniejsze cechy Sztucznego Życia:
Można by powiedzieć, że celem Sztucznego Życia jest tworzenie uogólnionego modelu życia, badanie „po prostu” życia, a nie życia na Ziemi. To bardzo ważne, bowiem ludzie mają głęboko zakorzenioną tendencję do odwoływania się zawsze do życia jakie znają – co często powoduje, że jakiekolwiek inne formy życia są albo uważane za niemożliwe, albo za nierealne, albo (w najlepszym razie) za gorsze (niedoskonałe podróbki życia). Funkcjonuje nawet pojęcie „szowinizmu węglowego” określające właśnie taką postawę, a także niemożność wyjścia poza ludzkie doświadczenia i obserwacje dotyczące życia na Ziemi. W związku z tym wiele osób zakłada, że jeśli mowa o sztucznym życiu, kreowaniu życia, lub tworzeniu modeli życia, to oczywiście chodzi o naśladownictwo życia ziemskiego – bo jakiego innego? Tymczasem nietrudno wyobrazić sobie sytuację, w której to nasz fenomen życia na Ziemi jest uważany za podróbkę i „niepełne” życie przez inne, dużo bogatsze i bardziej złożone życie. Skoro sami jesteśmy świadomi istnienia i możliwości budowania prostszych środowisk i form życia, nie powinniśmy też wykluczać ani istnienia, ani możliwości skonstruowania życia bardziej złożonego i zachwycającego – a więc, odwołując się do „szowinistycznego” podejścia – życia bardziej prawdziwego i cennego od naszego. Przytaczane często przykłady ewoluujących wirusów komputerowych, listów rozsyłanych przez ludzi (z gatunku przekonującego w swojej treści spamu), a nawet plotek, sądów lub idei które się rozpowszechniają – mają pokazać, jak pozornie abstrakcyjne twory mogą przejawiać właściwości tradycyjnie kojarzone z życiem (zdolność do powielania, mutowania, wymiany informacji, ewolucji, dopasowania do środowiska, metabolizmu). Tworzenie modeli służących badaniom życia ziemskiego (a zatem jego odwzorowywanie) jest jednym z celów Sztucznego Życia. Jednakże Sztuczne Życie to przede wszystkim kreowanie zróżnicowanych środowisk i form życia oraz szukanie odpowiedzi na pytanie, czy wolno nam termin „życie” ograniczyć i kojarzyć jedynie z biologicznym życiem ziemskim, i czy definicje życia oparte na biologicznym życiu ziemskim są wystarczające i pełne. Sztuczne Życie kontrastuje się z badaniami biologicznymi twierdząc, że badania biologiczne mają najczęściej charakter analityczny i polegają na dzieleniu złożonych zjawisk na prostsze mechanizmy tak, by ostatecznie móc zrozumieć owe zjawiska. W Sztucznym Życiu natomiast bardzo często doprowadza się do powstania złożonych systemów z prostych elementów, co często prowadzi do syntezy złożonych (niezrozumiałych) zachowań pomimo tego, że znamy szczegółowo wszystkie elementy podstawowe oraz relacje między nimi. Takie podejście wielokrotnie pozwoliło stworzyć sztuczne systemy zachowujące się w łudząco podobny sposób do systemów biologicznych. Oczywiście nie ma żadnej gwarancji, że podobne zachowanie w skali makro gwarantuje podobną budowę wewnętrzną – w ten sposób nie możemy od razu odkryć zasad działania danego biologicznego systemu. Pomimo to, takie podejście, choć może wydawać się niezbyt badawczym, niesie ze sobą olbrzymie korzyści. Po pierwsze, wiemy jak system biologiczny może być skonstruowany – i jest to prawdopodobnie najprostsza możliwa konstrukcja (badacze rzadko budują niepotrzebnie skomplikowane konstrukty). Po drugie, wiemy jak możemy badać system biologiczny, żeby potwierdzić lub sfalsyfikować konkretną hipotezę dotyczącą jego wewnętrznej budowy – możemy na przykład poddawać go działaniu określonych bodźców i porównywać zachowanie systemu naturalnego i sztucznego modelu. Takie postępowanie przydaje się przy próbach wyjaśnienia zjawisk budzących ciągle kontrowersje – kwestii powstawania gatunków, wielopoziomowej selekcji, zachowań stadnych i komunikacji międzyosobniczej itp. Stwierdzenie, że w symulacji komputerowej stworzonej przez człowieka obserwowane są identyczne zachowania jak w biologicznym systemie, pozwala często uniknąć ryzykownych eksperymentów myślowych, argumentacji „na sucho” i wieloletnich dyskusji (lub zaciekłych sporów) opartych na intuicjach.
Tematyka badań Sztucznego Życia jest tak szeroka jak szerokie jest pojęcie życia; wymieńmy podstawowe obszary zainteresowań:
Jak widać, lista ta dotyczy całego spektrum życia, od cząsteczek chemicznych po ekosystemy i społeczności. Widoczne są zarówno wątki biologiczne jak i technologiczne, a w oczy rzuca się często występujące słowo „ewolucja”. Wszędzie tam gdzie występuje słowo „sztuczne”, chodzi o badanie uogólnień procesów i praw znanych z naszego świata. Sztuczne Życie jest w sposób oczywisty kierunkiem interdyscyplinarnym, wymagającym od badaczy niemałej wiedzy ze względu na złożoność materii jaką się zajmują oraz ciągłej chęci poszerzania horyzontów i działania na styku różnych dziedzin. Wśród naukowców zajmujących się Sztucznym Życiem znajdziemy biologów, fizyków, chemików, informatyków, inżynierów, ekonomistów, lingwistów, kognitywistów, psychologów, matematyków, antropologów, filozofów, artystów i przedstawicieli innych dyscyplin. W badaniach Sztucznego Życia można wyróżnić dwa główne nurty:
Pierwszy z nich jest bardziej poznawczy, drugi – pragmatyczny, związany z zastosowaniami. Badań reprezentujących nurt pierwszy jest tak wiele, jak wiele jest zagadek w biologii i modeli wartych odkrycia. W kolejnej części artykułu skupię się na kilku wybranych modelach drugiego nurtu.
2. Algorytmy inspirowane biologicznieW informatyce jest wiele algorytmów, których pochodzenie wiązane jest z inspiracją naturą. Niekiedy trudno stwierdzić, czy dany algorytm powstał jako próba naśladownictwa natury, czy też powstał w zdroworozsądkowy sposób, a później skojarzył się z istniejącym procesem i został analogicznie nazwany. Algorytmy inspirowane biologicznie nie zajmują w informatyce jakiegoś szczególnego miejsca, mogą być zastępowane innymi algorytmami lub mieszane z nimi tworząc rozwiązania hybrydowe. Można jednak pokusić się o pewną charakterystykę algorytmów inspirowanych biologicznie: są one często odporne na zakłócenia (niedoskonałe dane, zmienne warunki, niepewność informacji) i zwykle nie prowadzą do uzyskania ściśle optymalnych (najlepszych możliwych) rozwiązań. Ponadto dosyć często mają charakter rozproszony, zdecentralizowany, są skalowalne, a rozwiązania uzyskane w wyniku ich działania mogą cechować się nadmiarowością (czasem złudną) i trudnymi do wykrycia zależnościami. Poniżej przedstawię trzy przykładowe klasy algorytmów inspirowanych biologicznie: algorytmy ewolucyjne, algorytmy mrówkowe oraz sztuczne układy odpornościowe.
2.1. Algorytmy ewolucyjne (genetyczne) i koewolucyjneZadziwiająco wiele sytuacji z jakimi spotykamy się w życiu codziennym, starając się znaleźć dla nich najlepsze wyjście, daje się sprowadzić do ogólnego problemu poszukiwania najlepszego rozwiązania w zbiorze rozwiązań dopuszczalnych. Rzadko kiedy myślimy w takich kategoriach o naszych problemach – rzadko staramy się wyobrazić wszystkie możliwe postępowania, ocenić każde z nich, porównać je i wreszcie zidentyfikować najlepsze. Taka „siłowa” metoda nie jest może specjalnie wyrafinowana, ale na pewno skuteczna. Thomas Edison podsumowując swoje żmudne i nie przynoszące sukcesu badania nad skonstruowaniem wytrzymałego włókna żarówki stwierdził, że bynajmniej nie odniósł porażki – po prostu odkrył 10 000 niedziałających rozwiązań. Zwróćmy uwagę, że w pewnym sensie przy takim podejściu następuje zamiana problemu jakościowego (wynalezienie nowego rozwiązania, pewien akt tworzenia, odkrycie) w ilościowy (znajdę najlepsze rozwiązanie systematycznie sprawdzając wszystkie możliwości). Wiedząc o tym, że przełomowy wynalazek powstał w wyniku przetestowania wszystkich kombinacji kilkunastu czynników – nie bylibyśmy skłonni docenić wynalazcy tak bardzo, jak byśmy to zrobili uważając że on swój wynalazek „wymyślił”, „odkrył”, albo skonstruował. W dzisiejszych czasach możemy zaimplementować program symulujący zachowanie żarnika w zależności od jego składu, płynącego prądu i innych czynników. Program byłby w stanie oszacować trwałość włókna, jasność i temperaturę barwową emitowanego światła, a zatem... moglibyśmy „wynaleźć” najlepszą żarówkę nie dokonując żadnego eksperymentu w realnym świecie, bazując jedynie na znanych prawach fizyki. Ile by to trwało? Zależy od tego ile możliwości konstrukcji żarnika chcielibyśmy sprawdzić oraz ile trwałaby ocena każdej z tych możliwości. Czy takie postępowanie nosiłoby znamiona inteligencji? Raczej nie. Czy wyniki uzyskane w ten sposób mogą konkurować z wynikami uzyskanymi innymi metodami (odkrycia, „wymyślenia” rozwiązania)? Dysponując odpowiednią ilością czasu (odpowiednio szybkim komputerem) uzyskamy najlepsze możliwe rozwiązanie, prawie na pewno lepsze od wszystkiego, co byliśmy w stanie wymyślić. „Komputer jest głupcem, który braki w inteligencji nadrabia szybkością” – ale czy trzeba naprawdę sprawdzać wszystkie możliwe rozwiązania? Okazuje się, że nie zawsze, a przede wszystkim, nie zawsze tak bardzo zależy nam na odkryciu tego najlepszego rozwiązania. Nie wnikając w liczne (i skądinąd bardzo interesujące) pomysły unikania siłowego przeszukiwania wszystkich alternatyw, wyjaśnijmy, co ma do tego ewolucja. Organizmy żyjące na Ziemi są pewnym niewielkim podzbiorem zbioru wszystkich możliwych organizmów jakie dałoby się zakodować używając DNA. Konkurując ze sobą i podlegając zmianom genetycznym podczas rozmnażania uczestniczą w ciągłej ewolucji, podobnie jak ewolucji podlegają wojenne techniki ataku i obrony czy też techniki wykonywania skoków narciarskich. Pomysł na ewolucję w komputerze jest prosty: zamiast sprawdzać olbrzymią liczbę wszystkich możliwych rozwiązań danego problemu, stwórz niewielki zbiór (populację) tych rozwiązań, a następnie zmieniaj je (mutuj), wymieniaj je częściami (krzyżuj), oceniaj, a przede wszystkim powielaj (rozmnażaj) te, które są najlepsze w populacji.
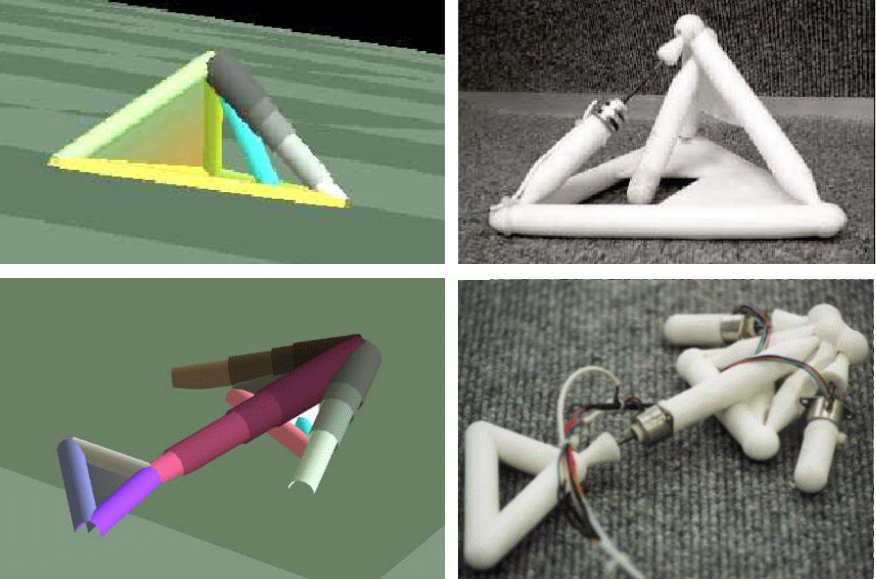
Taki cykliczny proces znany pod nazwą algorytmu ewolucyjnego (lub genetycznego, choć nazwy te ściśle biorąc nie są jednoznaczne) prowadzi najczęściej do skupienia się populacji rozwiązań w pewnym rejonie całej przestrzeni wszystkich „pomysłów”, w którym przeważają rozwiązania bardzo dobre (Rys. 2). I tak, zamiast odkryć najlepszą żarówkę sprawdzając wszystkie możliwości, możemy odkryć prawie najlepszą żarówkę dzięki ewolucji wirtualnych żarówek w komputerze – i przy okazji zaoszczędzić wiele czasu unikając testowania żarówek złych i bardzo złych. Należy zauważyć, że takie ewolucyjne podejście może być też stosowane do ograniczenia liczby testów w realnym świecie (tzn. w podejściu analogicznym do opisanych wyżej badań Edisona) – nie tylko w wirtualnej, symulowanej rzeczywistości. W wyniku stosowania algorytmów ewolucyjnych [4] w ostatnich latach powstają rozwiązania najróżniejszych problemów – lepsze niż te, jakie byli w stanie dotychczas skonstruować ludzie. Warto zwrócić uwagę, że do wykorzystania podejścia ewolucyjnego musimy umieć ocenić na komputerze każde potencjalne rozwiązanie, natomiast nie musimy wbudowywać w algorytm ewolucyjny żadnej, tradycyjnie istniejącej i przez wiele lat udoskonalanej, wiedzy na temat tego jak budować dobre rozwiązania w danym problemie. Zatem potrzebujemy symulatora żarówki oraz sposobu na krzyżowanie i mutowanie składu żarników, ale nie potrzebujemy wpisywać w algorytm jakiejkolwiek „sztuki” budowania żarników czy wiedzy dziedzinowej. Pozwala to uniknąć algorytmowi obciążeń związanych z wiedzą przekazywaną z pokolenia na pokolenie – dla niego wszystkie pomysły są równouprawnione. Z kolei dla człowieka-konstruktora pierwszeństwo mają pomysły nawiązujące do obecnego stanu wiedzy i doświadczenia. Oczywiście algorytmy ewolucyjne mogą oceniać rozwiązania pod kątem wielu kryteriów – jakości, ceny, wytrzymałości, szacowanego czasu produkcji, ergonomii itd.; najtrudniej zawrzeć w algorytmie ocenę estetyki i kilku innych kryteriów które człowiek-konstruktor uwzględnia nieświadomie. Dlatego rozwiązania uzyskiwane przez algorytmy genetyczne są często lepsze od tych tworzonych przez ludzi, ale są też zaskakujące, dziwne, nieszablonowe, ...kreatywne. Bywają patentowane, co świadczy o ich oryginalności. Algorytmy ewolucyjne są też wykorzystywane w celu uniknięcia problemów z rozwiązaniami opatentowanymi (znany przypadek z anteną Wi-Fi) – po co płacić wynalazcy skoro znając zasady można sobie samemu „wyewoluować” konkurencyjne rozwiązanie? Ze względu na ogólność opisanego podejścia algorytmy ewolucyjne bywają odważnie nazywane „automatem do wynalazków” i są stosowane właściwie we wszystkich dyscyplinach – elektronice, inżynierii, medycynie, ekonomii, itd. Wymieńmy kilka konkretnych osiągnięć – uzyskano pamięci USB o 30-krotnie wyższej trwałości; światłowody o dwukrotnie większym paśmie dzięki zastosowaniu otworów o dziwnych, kwiecistych kształtach (zamiast wcześniej stosowanych sześciokątnych); lepsze kile, turbiny, śmigła, skrzydła, obiektywy, implanty ślimakowe, wzmacniacze, filtry, anteny... Nie wspominając o dziedzinach w których człowiek nie ma dużego doświadczenia, takich jak tworzenie algorytmów dla komputerów kwantowych. O ile nie włączymy kryterium prostoty (np. kary za złożoność rozwiązań) do procesu ewolucyjnego, będziemy w stanie rozróżnić rozwiązania wyewoluowane od tych zbudowanych przez człowieka. Człowiek będzie tworzył rozwiązania możliwie proste, symetryczne i estetyczne; ewolucja da w wyniku rozwiązania zbudowane chaotycznie, z elementami nadmiarowymi i pozornie nadmiarowymi – rozwiązania, które ludziom często trudno jest zrozumieć. Dlatego człowiek w pierwszym odruchu usiłuje ulepszać i upraszczać rozwiązania wyewoluowane, by ku swojemu zaskoczeniu przekonać się, że to co wydawało się zbędne i niezależne od reszty, okazuje się być istotnym elementem misternie powiązanym z innymi fragmentami rozwiązania.
Niewątpliwie jesteśmy dopiero na początku drogi. Czy zamiast ewoluować rozwiązanie, można dokonać ewolucji metody, która rozwiązanie zbuduje? Tak, można. Wtedy ewolucji będzie podlegała wiedza jak budować dobre rozwiązania, a nie same rozwiązania. Czy można prowadzić koewolucję kilku populacji tak, by były dla siebie konkurencją i ciągle utrzymywały presję? Czy można stworzyć kilka populacji, które współpracują między sobą? Czy można zamodelować określone środowisko z ograniczonymi zasobami, o które będą konkurowały rozwiązania, unikając w ten sposób potrzeby bezpośredniego definiowania kryteriów oceny rozwiązań? Na wszystkie te pytania odpowiedzi są twierdzące. Często nie zdajemy sobie sprawy, że w urządzeniach których używamy na co dzień zastosowano elementy powstałe dzięki opisanemu powyżej podejściu – a są to skromne początki. W Sztucznym Życiu wyróżniliśmy dwa nurty – praktyczny (jego wyrazem są właśnie przedstawione algorytmy ewolucyjne) i badawczy. Ten drugi nurt w kontekście ewolucji obejmuje tworzenie i badanie różnych modeli ewolucji po to, by udzielić odpowiedzi na rozmaite pytania – na przykład: Czy ewolucja jest powtarzalna? Czy przebiega liniowo, czy skokowo? Czy przy niezmiennych warunkach zewnętrznych osiąga stabilizację? Czy komplikuje, czy upraszcza organizmy? Czy organizmy późniejsze są lepsze od wcześniejszych? Czy powstają organizmy odporne na zmiany warunków zewnętrznych? itp.
2.2. Algorytmy mrówkowe i inteligencja grupowaInteligencja grupowa, nazywana też czasem inteligencją roju (swarm intelligence) obejmuje podejścia, w których zachowanie inteligentne wynika ze współdziałania wielu prostych osobników (agentów). Natura dostarcza nam wielu przykładów społeczności organizmów, w których pojedyncze osobniki są nieświadome całości zadania w jakim uczestniczą, natomiast ich liczność oraz specyficzne zachowanie prowadzi do wykonania tego zadania. Systemy oparte na takim podejściu przejawiają cechy o których pisałem wcześniej: osobniki wykonują zadanie w sposób skuteczny ale niekoniecznie ściśle optymalny, a systemy są odporne na zakłócenia i są skalowalne (sterowanie liczbą osobników wpływa na jakość i sposób wykonania zadania). Brak centralnego sterowania – istotna właściowość tego paradygmatu, oraz swoisty „brak nadzoru” nad sposobem wykonania zadania, są nietypowe dla tradycyjnych rozwiązań informatycznych. Przypadkowy charakter działania całego systemu oraz brak stuprocentowych gwarancji co do czasu i jakości wykonania zadania są w istocie cechami systemów naturalnych, ale w kluczowych zastosowaniach, gdzie rolę grają pieniądze lub zdrowie człowieka, takie podejścia są niechętnie stosowane. Można dyskutować, czy tradycyjne podejścia są faktycznie bezpieczniejsze od tych inspirowanych biologicznie. Porównajmy obie koncepcje na przykładzie zadania zbierania kawałków drewna w jedno wyznaczone miejsce. Wyobraźmy sobie pewien model świata (Rys. 4) w którym kawałki te są przypadkowo porozrzucane, w każdym miejscu może leżeć co najwyżej jeden kawałek, a celem jest ich zebranie w jednym obszarze przy pomocy pewnej liczby robotników (np. robotów lub „termitów”). Tradycyjne podejście wymaga ustalenia miejsca zbiórki drewna, a następnie zaprogramowania wszystkich robotów tak, by przemierzały świat za pomocą określonego algorytmu w poszukiwaniu pojedynczych kawałków drewna, podnosiły je, a następnie w oparciu o swoją bieżącą pozycję i pozycję miejsca zbiórki wyznaczały odpowiedni kierunek. Idąc w stronę sterty, roboty musiałyby rozróżnić przypadkowo porozrzucane kawałki drewna od miejsca, gdzie zaczyna się sterta – wbrew pozorom, niełatwy problem.
Takie tradycyjne podejście do zadania zbierania drewna jest trudne do zaimplementowania, ale nosi na sobie znamię przemyślanego, systematycznego, logicznego postępowania. Mozolnie ulepszając taki algorytm dostaniemy ostatecznie upragniony efekt i jako twórcy algorytmu będziemy w miarę przekonani co do jego skuteczności. Jest zaskakujące, że radykalnie odmienne podejście, nie wymagające od robotów wiedzy o tym gdzie się znajdują ani gdzie jest sterta, da podobny efekt. Przepis dla robota brzmi: poruszaj się po świecie przypadkowo. Jeśli nadepniesz na kawałek drewna, podnieś go. Jeśli niosąc kawałek drewna nadepniesz na inny – połóż swój kawałek na wolnym miejscu obok. To wszystko! Ten skrajnie prosty przepis prowadzi do „wyłonienia się” sterty w dosyć przypadkowym miejscu (Rys. 5) pomimo tego, że uczestnicy procesu nie są absolutnie świadomi jaki jest zamierzony efekt ich działań. Zjawisko to nosi nazwę emergencji. Powstała sterta nie będzie zapewne tak elegancka jak w tradycyjnym podejściu, nie będzie również tak stabilna (kawałki drewna na brzegach mogą być ciągle przenoszone przez robotników), zwróćmy za to uwagę jak wiele można popsuć zakłócając w różny sposób wiedzę agentów w tradycyjnym podejściu, i jak niewiele można zakłócić w podejściu bez nadzoru.
W powyższym, niezbyt praktycznym przykładzie (nieczęsto informatycy programują roboty zbierające drewno na stertę), zadanie jest wykonywane przez wiele agentów – stąd nazwa agent-based modeling (ABM). Podejście niescentralizowane ilustruje dobrze sytuację, gdzie całość jest czymś więcej niż sumą części składowych: za „sumą” kryje się na tyle specyficzny (można by powiedzieć: „nieliniowy”) sposób lokalnych interakcji agentów ze sobą i ze środowiskiem, że prowadzi on do nieoczekiwanego całościowego, globalnego efektu. Podobne podejście wykorzystywane jest w stosunkowo nowych algorytmach optymalizacyjnych – algorytmach mrówkowych [3], gdzie wyimaginowane mrówki budują wspólnie rozwiązanie problemu, wybierając samodzielnie jedynie dobre fragmenty rozwiązania, i informując za pomocą wirtualnego feromonu o jakości całego rozwiązania. Efektywność tych algorytmów jest porównywalna z istniejącymi, tradycyjnymi podejściami. Paradygmat inteligencji grupowej kusi niewielkimi wymaganiami co do niezawodności komunikacji, nie wymaga globalnej informacji ani ciągłej wiedzy o stanie procesu. Można powiedzieć, że nie wymaga... serwera, stąd jest atrakcyjny np. w sieciach bezprzewodowych tworzonych ad hoc, które są rozproszone, dynamiczne, bez centralnego planowania, o ograniczonych zasobach i niepewnej komunikacji. Również w robotyce jest to obecnie intensywnie rozwijający się dział [1] – samoorganizujące się i współpracujące grupy robotów, gdzie prostota przekłada się zarówno na odporność na zakłócenia, jak i na niską cenę i możliwość masowej produkcji. Wiele klasycznych problemów informatycznych (np. sortowanie), doskonale przebadanych i rozwiązanych na dziesiątki sposobów, można również rozpatrywać w opisanej powyżej, alternatywnej perspektywie.
2.3. Sztuczne układy odpornościowe (systemy immunologiczne)System immunologiczny [2] jest rozproszonym układem posiadającym zdolność uczenia się, adaptacji, i zdolnym do rozproszonej, progowej detekcji różnego rodzaju anomalii. System ten zmienia się i ewoluuje, tworząc samoorganizującą się pod wpływem patogenów sieć. Infekcje, których doznajemy, są zarazem próbą i nauką dla naszego układu odpornościowego. W informatyce model układu odpornościowego przydaje się wszędzie tam, gdzie zachodzi potrzeba wykrywania anomalii. W szczególności może to oznaczać nietypowe działanie systemu operacyjnego spowodowane przez podejrzanie działający program (program błędnie napisany lub wirus). Ogólniej, sztuczny układ odpornościowy odpowiada sytuacjom, w których chcemy odróżnić przypadki „swoje” od „wrogich”, albo dobre od złych. Takich sytuacji jest oczywiście wiele, od rozpoznawania niebezpiecznych programów, przez wykrywanie listów reklamowych, monitorowanie biura i analizę obrazów z kamer, identyfikację nietypowych sytuacji w samolocie dzięki analizie odczytów z czujników, aż po kompresję informacji – bo przecież wiedza zawarta w nauczonym systemie immunologicznym to zwarta postać opisu dobrych lub złych przypadków. Najpierw, na etapie selekcji negatywnej, tworzy się pewną liczbę detektorów (przeciwciał), które nie rozpoznają żadnego z dobrych przypadków. Podczas pracy systemu, jeśli nadchodzący, nowy przypadek jest odpowiednio blisko jakiegoś detektora – zostaje uznany za „zły”, a uaktywniony detektor (lub detektory) w procesie selekcji klonalnej ulega powieleniu i mutacjom. W ten sposób system wzmacnia swoją reakcję na antygeny, z którymi się zetknął. Oczywiście jeśli dysponujemy negatywnymi przypadkami (antygenami) wcześniej, zanim uruchomimy system – możemy już na nich dokonać wstępnego „uczenia” układu odpornościowego. Jeśli ich nie mamy, możemy zacząć używać systemu nauczonego jedynie na pozytywnych przykładach. W każdym razie wychodzimy z założenia, że wszystko co nie przypomina znanej, normalnej sytuacji (pozytywnego przypadku lub komórki macierzystej) jest anomalią.
3. Refleksje nad Sztucznym ŻyciemW badaniach i algorytmach opisanych w niniejszym artykule nie ma metafizyki: są one wykorzystywane w praktyce i mogą być wielokrotnie powtarzane – być może dlatego człowiek traktuje je jako część świata technologii. To coś dzieje się gdzieś w komputerze, zatem nie zasługuje na specjalną uwagę, a już na pewno nie na poważne traktowanie należne istotom żywym (por. [9]). Ów szowinizm węglowy, o którym była wcześniej mowa, jest bardzo silnie zakorzeniony – sam nieustannie przekonuję się, jak trudno jest wyjść poza ustalony schemat rozpoznawania fenomenu życia. Doświadczenie podpowiada, że człowiek bez pomocy specjalnych narzędzi nie będzie w stanie rozpoznać nawet bardzo zaawansowanych form życia, o ile nie będą zbliżone do życia ziemskiego. Potrzebujemy mikroskopu by zobaczyć organizmy, których nie dostrzegamy gołym okiem; bez mikroskopu możemy jedynie liczyć, że zobaczymy pośrednie efekty ich istnienia. A czego potrzebujemy by dostrzec życie istniejące w pamięci komputera? Czy jesteśmy na tyle pewni siebie, by skreślić możliwość istnienia życia w takim środowisku? Czy odkryjemy życie na innej planecie, czy też wylądujemy na tamtejszych organizmach uważając ją za martwą? Człowiek jest niezmiernie przywiązany do tego co widzi i czuje; wystarczy zmienić nieco reprezentację świata, odbić obraz, zamienić wymiary, pokolorować inaczej – i dostrzegamy jedynie chaos, który jest przecież tym samym życiem, przetransformowanym jedynie do postaci, do której nie byliśmy przyzwyczajeni. W filmie The Matrix [8] pokazano świat, do którego przywykliśmy oraz świat zielonych spadających symboli – to są dwie reprezentacje tego samego świata, lecz nie łudźmy się, że w owych symbolach odkrylibyśmy cokolwiek interesującego. Komputery przekroczyły zdolności intuicyjnego rozumienia człowieka już na początku ich rozwoju. Zaledwie kilka, kilkanaście sztucznych neuronów połączonych ze sobą w skomplikowany sposób stanowi materiał do wielogodzinnych, żmudnych analiz. Tymczasem obecnie mamy terabajty pamięci w komputerach i jesteśmy w stanie symulować złożone środowiska i procesy ewolucyjne, które zagospodarowują tą pamięć wirtualnymi, wysoce zorganizowanymi konstruktami (por. środowisko Avida, rozdział 1 [5]). Trudno znaleźć słowa, by opisać przepaść jaka nas dzieli od pełnego ogarnięcia tych wirtualnych środowisk... pozostaje ich obserwacja lub ignorancja, bo na dogłębne analizy nie mamy czasu, środków ani chęci. Studia biologiczne nad życiem ziemskim trwają od zarania ludzkości, ale przecież nie zatrudnimy podobnej liczby naukowców do badania wirtualnych ekosystemów! Zatem po co w ogóle tworzyć symulacje wykraczające poza możliwości analizy? Część badań ma ściśle określone cele i zgodnie z dobrą praktyką eksperymentatora, modele są możliwie proste – takie, by objąć zjawisko podlegające badaniu. Tym samym Sztuczne Życie oferuje użyteczne metody weryfikacji hipotez dotyczących życia ziemskiego, które pomagają rozstrzygnąć istniejące spory i wątpliwości. Jednak człowiek, który zawsze kreował swoje „małe światy” i symulacje rzeczywistości, nie chce ograniczać się do wiernego odzwierciedlania w nich ziemskich realiów. Nie chce też definiować szczegółowo wszystkich zasad panujących w wirtualnych światach. Badacze zamierzają raczej sprawdzić, do czego zdolna jest swobodna ewolucja w coraz bardziej złożonych środowiskach, gdzie minimalizowane są ograniczenia konstrukcyjne sztucznych form życia, a maksymalizowane możliwości ich interakcji ze sobą i z otoczeniem. Analiza wyników sprowadza się tu do obserwacji stanu środowiska, a zatem jest wysoce niedoskonałą metodą odkrywania interesujących fenomenów ze względu na liczne ograniczenia i przyzwyczajenia człowieka. Wiemy, że powstają bardzo złożone struktury, ale bez żmudnych, subiektywnych badań nie potrafimy ocenić na ile one są „ciekawe” i wartościowe – bowiem nie dysponujemy na razie ogólnymi miarami czy też detektorami życia (ani też detektorami inteligencji, świadomości, emocji, uczuć). Co prawda trwają prace nad stworzeniem ogólnych „mierników” życia, ale może się paradoksalnie okazać, że innego życia nie zauważymy albo nie docenimy – chyba że będzie na tyle zaawansowane, że to ono nawiąże z nami kontakt. Bibliografia/References
|